AI/ML - Neural Style Transfer
Turing Game of Thrones Characters into White Walkers with AI
 Eanna Mulrooney
Eanna Mulrooney
In the HBO TV series Game of Thrones, characters get turned into zombie like creatures called white walkers. Unfortunately, some of the more annoying characters don’t end up making this permeant “lifestyle” change. So let’s look at a machine learning algorithm that can help us create a world where some of these actors meet an entirely different fate…
*This article is intended to be beginner friendly for anybody just starting out on their ML journey or new to style transfer. It aims to create a deeper intuition on core concepts using visual representations and code examples.
ML Background
Neural style transfer takes the abstract style of one image and applies it to the content of a second image. This technique was first published in the paper “A Neural Algorithm of Artistic Style” by Leon A.Gatys, Alexander S. Ecker, Matthias Bethge but you probably know it best from the Van Gogh example or from using the Prisma app.

The algorithm requires three images: a Content Image, Style Image, and an Input Image(usually a copy of the Content Image). We will update the Input Image so that it keeps the main features of the Content Image and receives the abstract style of the Style Image. For a change of pace, we will use this technique to try and turn popular Game of Thrones character John Snow into a humanoid ice creature known as a White Walker! Using a stock image of John Snow as the Content Image and a drawing of a White Walker as the Style Image we can explore how this algorithm works and generate new story ideas for George R.R. Martin at the same time.
*You can jump to the end if you just want to see the results

I’ve included code snippets all the way through but you can check out the full codebase on the Github.
Overview — 6 Steps to Zombification
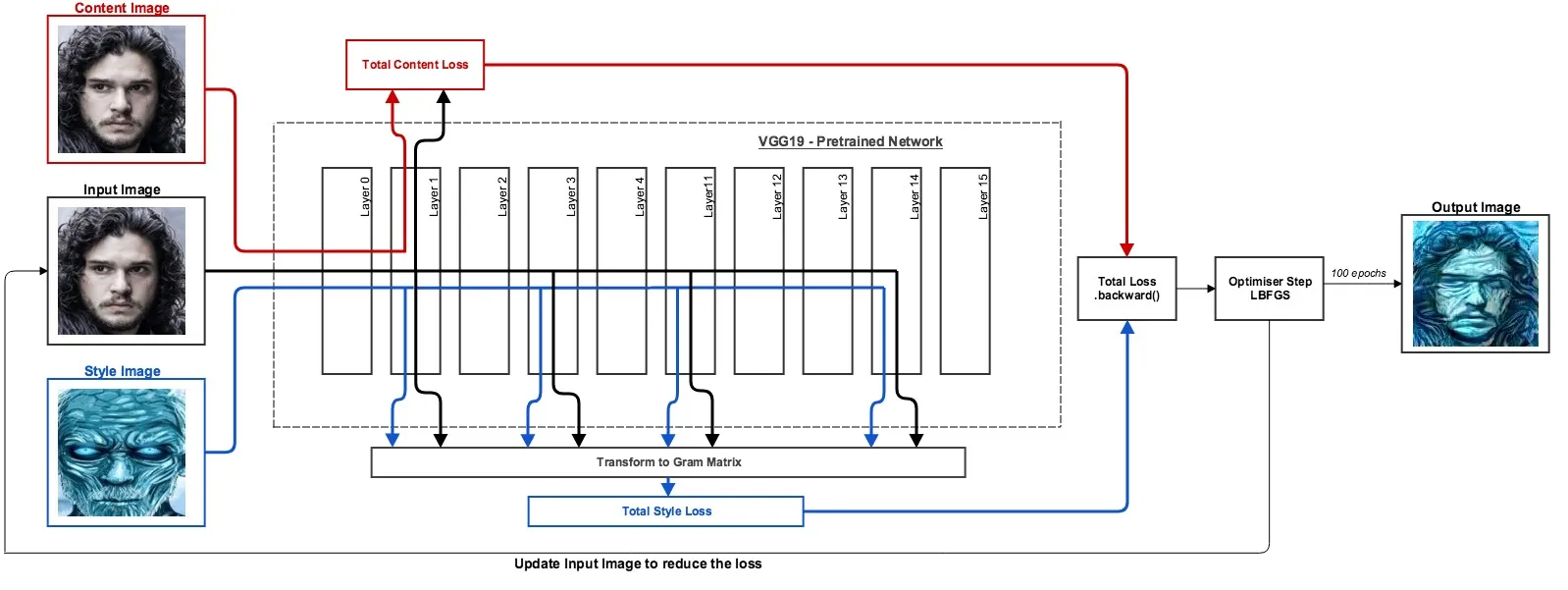
- Loss Function — Create a general loss function to tell us how different one image is from another.
- Optimiser — Create an optimiser that can update one image to make it look a little bit more like another image.
- Pre-trained Classifier — Download a pre-trained neural network (VGG19) and register hooks at specific layers.
- Content Loss — Create the content loss by putting the Input and Content Images through the VGG network then passing the outputs to the loss function.
- Style Loss — Create the style loss by putting the Input and Style Images through the VGG network. Transforming each output into a Gram Matrix(I’ll explain later) and then passing these to the loss function.
- Fire it up! — Combine both losses, backprop the total, step the optimiser, and repeat.
Step 1 — General Loss Function (How different are these two things?)
*Note: We’ll be using Python 3.6 and PyTorch. The code should be run in your Jupyter Notebook in order to view some of the animated outputs. Once you have those setup, pip install the modules in the requirements.txt in order to get things running.
First, some imports and helper functions that we will need for all the examples.
PyTorch requires us to turn our images into torch tensors so we need some helpers that we will use to resize images, turn them into torch tensors, add an extra dimension for the batch size, and also do the reverse so we can view torch tensors as images.
To create the loss function we need to compare the Input Image with a target (either the Content or Style Image). We can get the Mean Squared Error between the two by using PyTorch’s built in MSE loss function.
We now have a general loss function that can be reused. If you pass it two tensors the error will be returned (how different are they?).
Step 2 — The Optimiser (Make these two things a little more alike)
Now that we have our imports, helpers, and loss function we can create an optimiser, run our code, and see some outputs.
*Note: Both images used must be the same size (I made all my images 150x150).
- Load an Input Image(John Snow) and a target image(Night King).
- Put both images through the image_loader() helper to resize the images, turn them into torch tensors, and add another dimensions for batch size (required by PyTorch).
- Define how many epochs we want the optimiser to run for and what our optimiser function will be. We will be using a built in PyTorch optimiser called LBFGS to make the Input Image a little bit more like the target image with each epoch. The closure() function is there because LBFGS requires it. Basically, it does 1.25 optimisations per epoch but we don’t have to worry too much about that.
- For each epoch we pass the Input and target images to the loss function.
- Find out how different they are (calc_loss).
- Backprop the loss(loss.backward).
- Update the Input Image a small amount and repeat (optimizer.step).

We can see what happens after each step of the optimiser by passing the tensor to animate_output() and it will display
an image in the cell’s output. With each epoch the optimiser makes John Snow a little bit more like the Night King until
after 140 epochs when the image is now almost a pixel perfect image of the Night King .
Makes for a pretty cool .gif!
Using an optimiser to gradually decrease the loss is a core component in many amazing applications like self-driving
cars, and machine translation. We can also use this technique to solve equally important tasks like beating your 6 year
old at a game of spot the difference.

If we put both images through the optimiser we can see all the differences slowly appear.

So if that punk Jeremy challenges you to another game of spot the difference, you simply take a photo of both images, run to your apartment, upload them to your laptop, quickly put them through the optimiser, make a gif of the outputted images, watch as the differences appear, then stroll confidently back with the answers in mind. That’ll show him!
Step 3 — Download a Pre Trained Image Classifier
The Problem — Our optimiser will make our Input Image look exactly like the target image. A pixel perfect match. When we pass it our Style and Content Images it will make the Input Image a pixel perfect match of them as well. We don’t want that. We want to keep most of the spacial information from the Content Image (it needs to still kind of look like John Snow) and throw away the spacial information from the Style Image only keeping the texture, colour, line shapes etc. So, what tool can we use to to try to extract this information from our images?
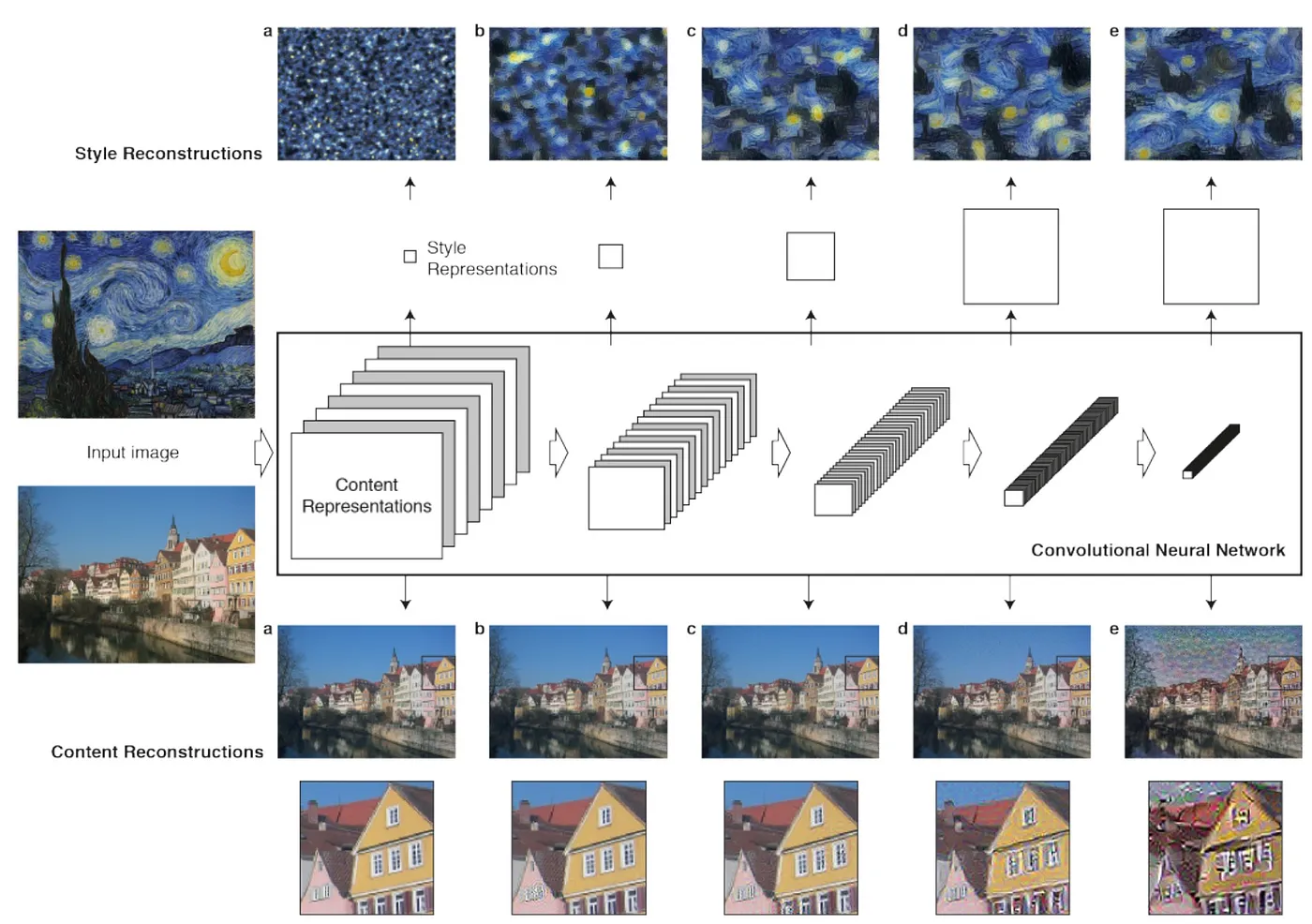
Solution — We will use Convolutional Neural Network that has been trained for object recognition. As an image gets passed through this network the image gets transformed into thousands of features that represent the general content of the image and not the exact pixel values of the image.
PyTorch has several pre-trained networks that we can download but we will be using VGG19.
The pre-trained VGG network will be downloaded and if you print(vgg19) you can see all the different layers.
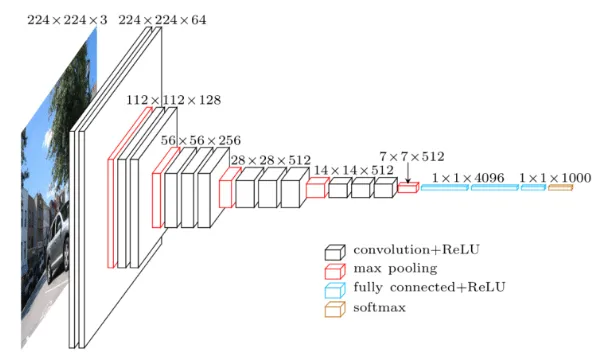
Now that we have a network we need to get the output of different layers as the images move through the network.
To do this we can register a forward hook at each Conv2d layer of the network. The reason we pick the output of the convolutional layers as opposed to after a MaxPool is because the Convolution layer contains the most information about the image at that point in the network. Max Pooling decreases the size of the tensor and we will loose some of the spatial information.
Step 4 — Content Loss
For the content loss we first need to put the Content Image through the VGG network and save the output of a certain layer. Then we will put the Input Image through the network, get the output at that same layer, and compare the two to get the content loss.
And if we modify our earlier optimiser we can visualise some of the features that activate each of the layers.
I used random noise as my Input Image to better show the features that get activated at different layers.

- Each one of the layers seems to be activated by different features.
- The earlier the layers look more like the Input Image as they’re closer to the pixels.
- The further we go through the network the more spatial information we lose and the more abstracted the features become.
We can pick any of the layers to optimise for but we will probably pick one of the earlier layers as it gives us the most features while leaving enough room to add our style later.
Step 5 — Style Loss
We will get the style loss in the same way as the content loss, by putting the Style and Input Images through the network and comparing the outputs at certain layers. The only difference is that we are going to:
- Use more than one layer for the style loss, then add all those losses together.
- Create a “Gram Matrix” for the output of each layer then pass those to the loss function.
But what is a gram matrix and why do we need it?
A gram matrix is a way to represent an image without the spacial information e.g does this image contain features of an
eye, regardless of where the eye’s located. For the gram matrix we flatten the features for each channel and do a dot
product. We do this because when you flatten the image array it instantly throws away the spacial info. So we can say
that if two images have similar styles, they will also have a similar gram matrix. Doing this we can get a more general
sense of the image without the specifics of a single layer/the spatial information.
Step 6 — Let’s put it all together and create some White Walkers
The final step is the easiest. We have all the components we need so the only thing we have to do is update the optimiser to combine the style and content losses, then run it!

We just created our first White Walker!
Now let’s make some more…


Try a different Style Image…


Neural Style Transfer is a great way of exploring machine learning techniques in a fun way. You can get started without a GPU, on any standard laptop. And best of all, because of the instant visual feedback, you start to develop an intuition for things like the learning rate, gradients, and layers in a neural net.
So play around with the code. See what happens!
- Adjust the learning rate.
- Try different Content and Style Images/weights.
- Use different layers in the network.
- Maybe even try an alternative to VGG19.
References:
- A Neural Algorithm of Artistic Style, Leon A.Gatys, Alexander S. Ecker, Matthias Bethge
Bonus question:

- What happened during this optimisation?
- What can we do to fix it?